
AI Researcher Swarm
A Swarm of AI Agents that autonomously conduct and publish research based on a single prompt.

Imagine having a team of AI agents that can take a single research prompt and handle everything—from finding sources and scraping data to analyzing information and publishing findings across platforms like Google Docs or SharePoint.
This AI Researcher Swarm automates the entire research and publishing process, powered by SwarmZero and integrations like Firecrawl and SerpApi, making research easy, fast, and hands-free. Perfect for anyone looking to simplify and scale their research workflows with AI.
Demo
Prerequisites
Python 3.11 or higher installed
Git installed
An IDE or text editor (e.g., VS Code, PyCharm)
Basic knowledge of Python programming
API Keys Needed:
Optional: MISTRAL_API_KEY, ANTHROPIC_API_KEY, GEMINI_API_KEY
This project uses gpt-4o by default, but you can easily swap it out for any of our supported models. Ensure to update the model name in the swarmzero_config.toml file.
SHAREPOINT_CLIENT_ID
SHAREPOINT_CLIENT_SECRET
SHAREPOINT_TENANT_ID
SHAREPOINT_SITE_ID
SHAREPOINT_DRIVE_ID
Enable the Google Docs API and Google Drive API for your project.
GOOGLE_SCOPES
GOOGLE_APPLICATION_CREDENTIALS
CONFLUENCE_BASE_URL
CONFLUENCE_ORGANISATION_ID
CONFLUENCE_USERNAME
CONFLUENCE_API_TOKEN
CONFLUENCE_SPACE_KEY
Ensure all environment variables are set in the .env file.
Features of AI Researcher Swarm
AI-Driven Research: Deploys multiple AI agents to conduct in-depth research from a single prompt, automating the entire process.
Service Integrations:
Google Docs: Publishes findings directly to Google Docs.
SharePoint: Manages and uploads documents to SharePoint.
Confluence: Publishes documentation and results to Confluence.
Automated Search & Scraping:
SerpAPI: Conducts Google searches automatically.
Firecrawl: Enables advanced web scraping and URL mapping.
Configuration Management: Streamlines configuration with environment variables for easy setup and control.

Step-by-Step Instructions to Build the AI Researcher Swarm
First, clone the repository containing the base code for building your dApp.
Step 1: Open your terminal or command prompt and run the following commands:
Copy
git clone https://github.com/swarmzero/examples.git
cd examples/swarms/researcher_swarmThese commands will download the repository and set up the directory to start working on the agent.
Setting Up the Environment
Now, set up the environment required to run the agent.
Step 1: Create a virtual environment:
Copy
python -m venv ./venvStep 2: Activate the virtual environment:
On Windows
Command Prompt:
Copy
venv\Scripts\activate.batPowerShell:
Copy
venv\Scripts\Activate.ps1
On Linux/Mac:
Copy
venv/bin/activate
Installing Dependencies
With the environment activated, install the required dependencies:
poetry installSetting Up Environment Variables
Step 1: Create a new file called .env in the root directory:
touch .envStep 2: Copy the contents of .env.example into your new .env file.
Step 3: Add your API keys to the .env file
Understanding the Code Structure
The codebase for the AI Researcher Swarm is organized into several key folders and files:
app Folder: Contains core functionalities of the AI Researcher Swarm.
tools: Holds specific modules for publishing outputs.
publishers: Includes integrations for publishing to various platforms.
confluence.py: Handles Confluence integration for document publishing.
google_docs.py: Manages Google Docs publishing.
sharepoint.py: Manages SharePoint document uploads.
tools.py: Contains helper functions for tool interactions.
structures.py: Defines data structures for organizing and managing agent workflows.
Configuration Files:
.env.example: Sample environment variable configuration.
swarmzero_config.toml: Configures the Swarm with agents and tools.
Main Scripts:
main.py: Runs the Swarm, initializing agents and coordinating tasks.
README.md: Documentation file explaining setup and usage.
Creating the App
In this section we will creating the essential tools that will be used by the Swarm to do the research and publish autonomously.
1. Structured Output - structure.py
2. Tools - tools.py
2a. Publisher Tools - publishers.py
Creating the Swarm
As the first step, set up the config file:
Follow the below code to setup the AI researcher Swarm:
Running the Swarm
Run the main application using:
poetry run python main.pyThis will initialize the AI agents, perform web searches, map URLs, scrape content, and publish the results to the configured platforms.
Example Prompts
When prompted, you can enter research queries like:
Research the history of the internet
Research crypto-economics and AI agent collaboration, publish to Google Docs
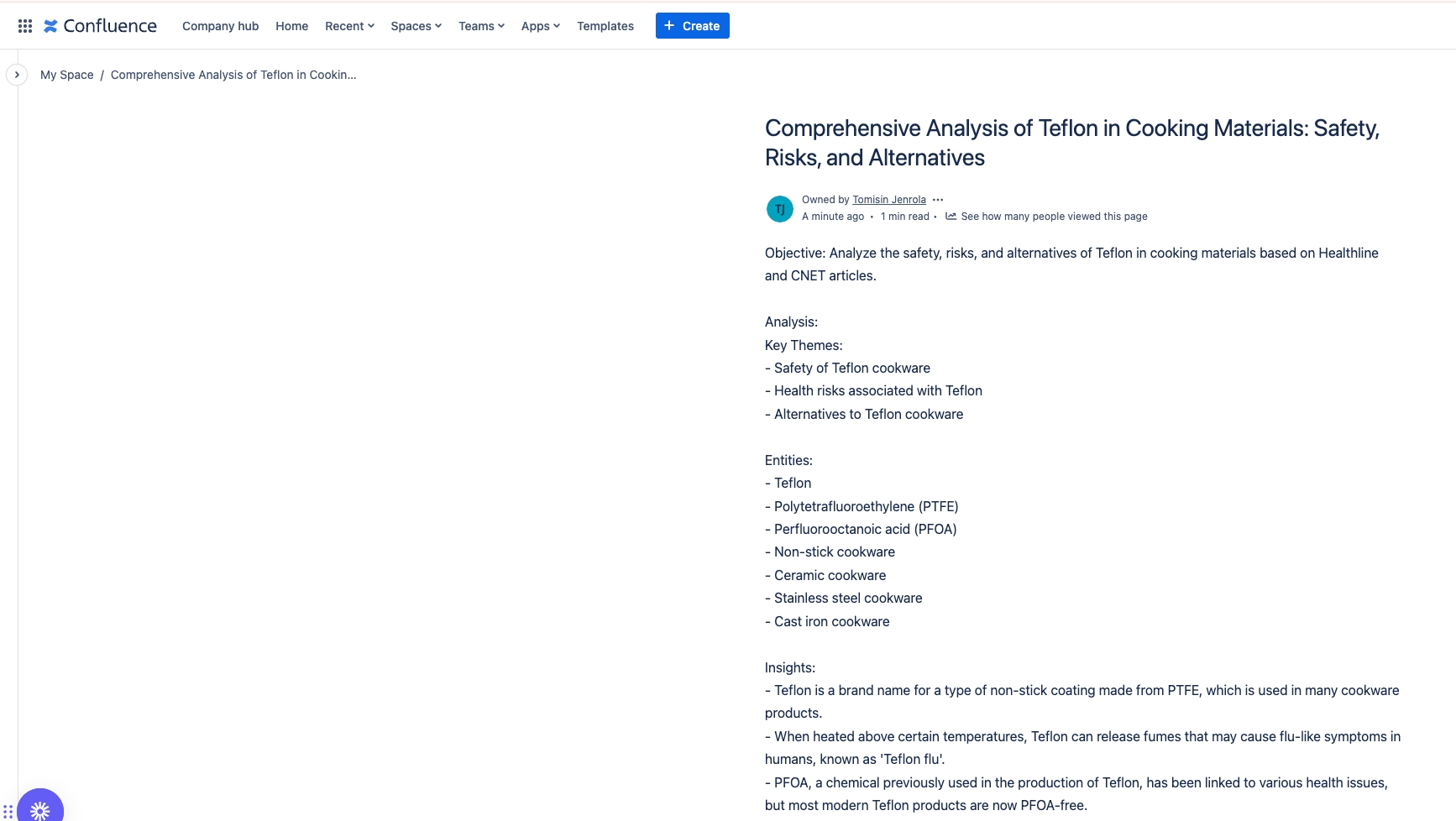
Research the history of the stock market and Federal Reserve, publish to Confluence
Research distributed model training for LLMs and publish to SharePoint
Each prompt will trigger the swarm to:
Search for relevant information
Extract and analyze content
Generate a comprehensive research document
Publish to your specified platform (it defaults to saving a PDF locally if not specified)
Example Outputs
Local PDF
More generated PDFs can be found in the sample outputs folder.
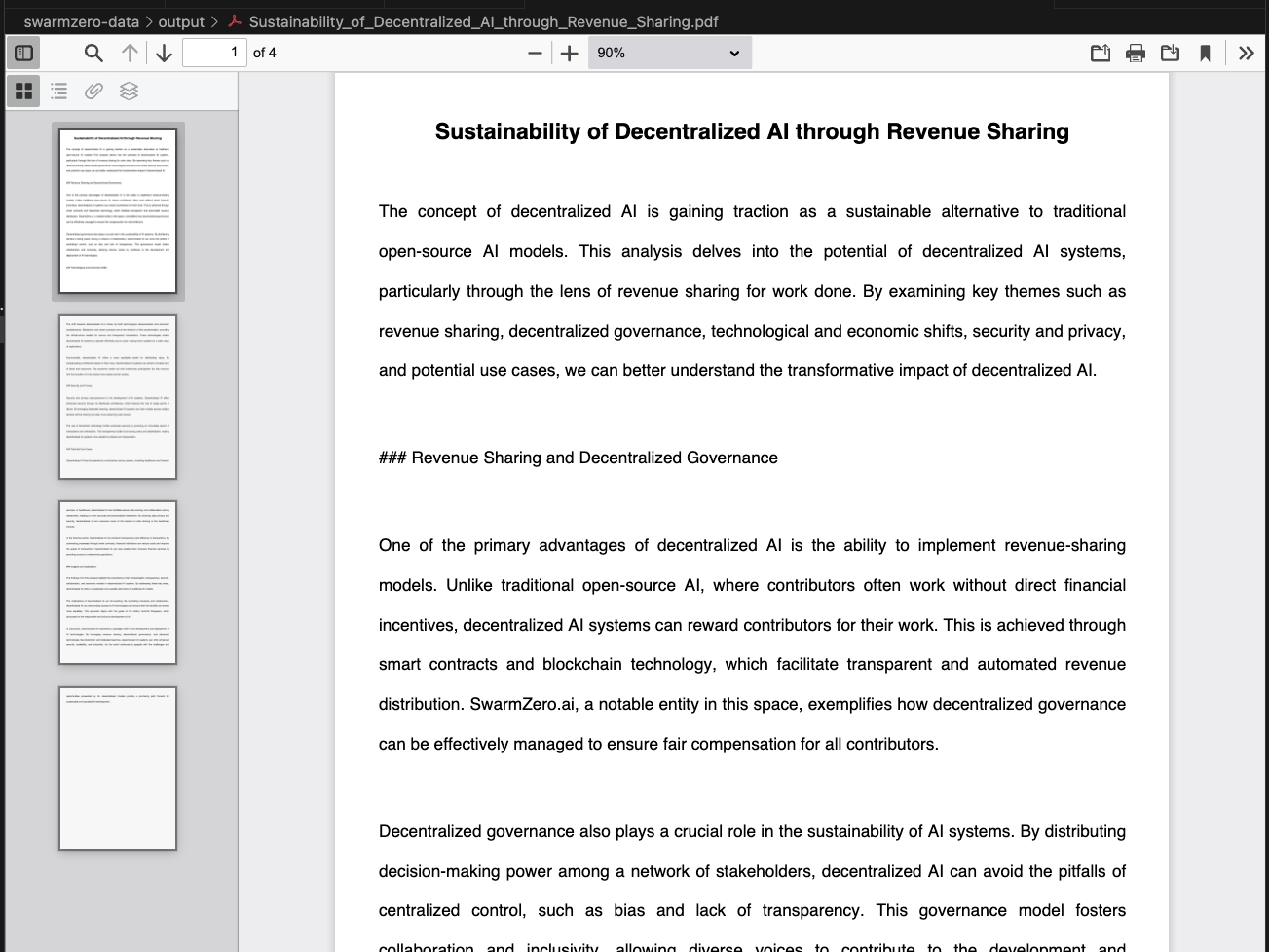
Google Docs
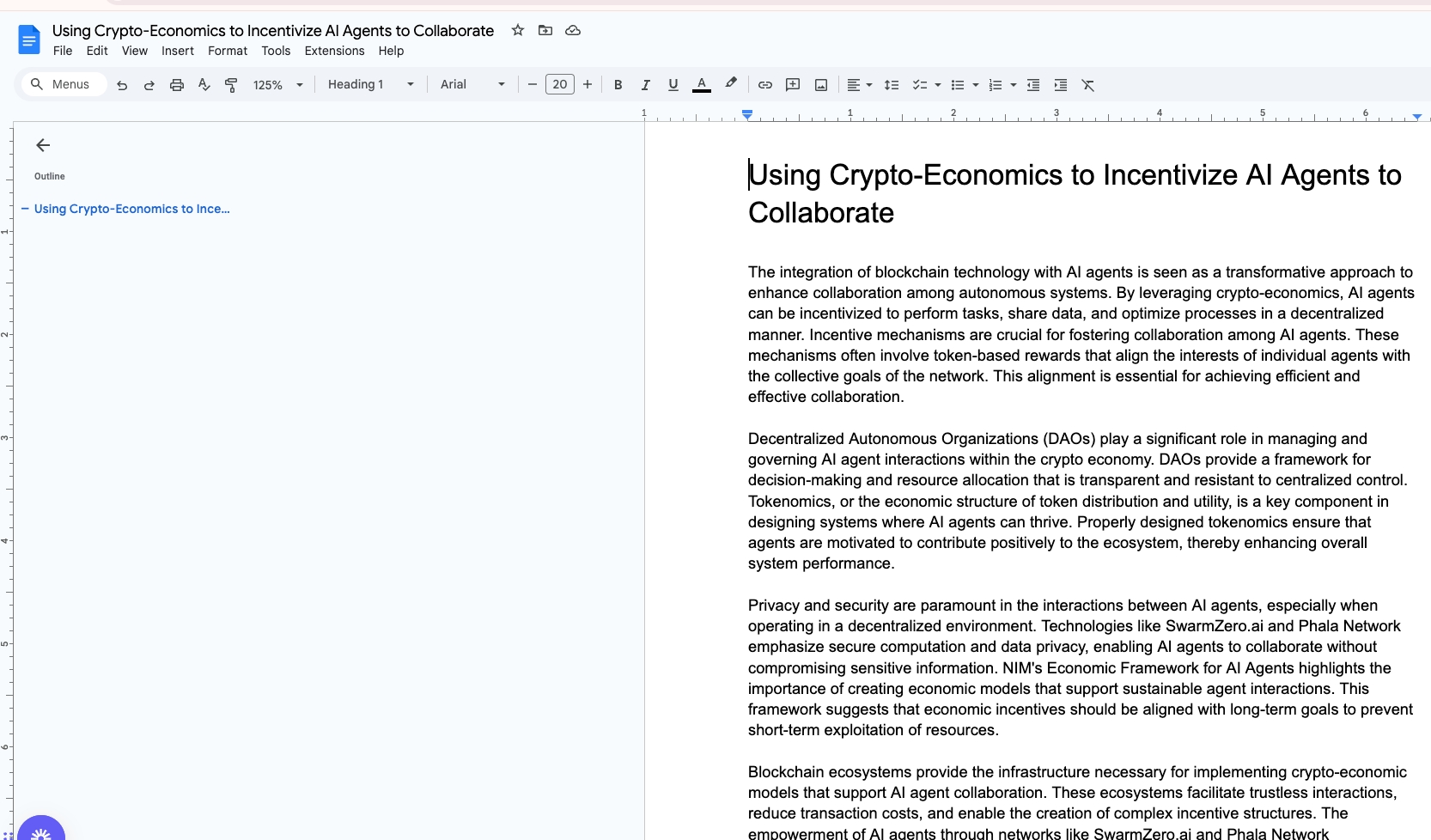
SharePoint
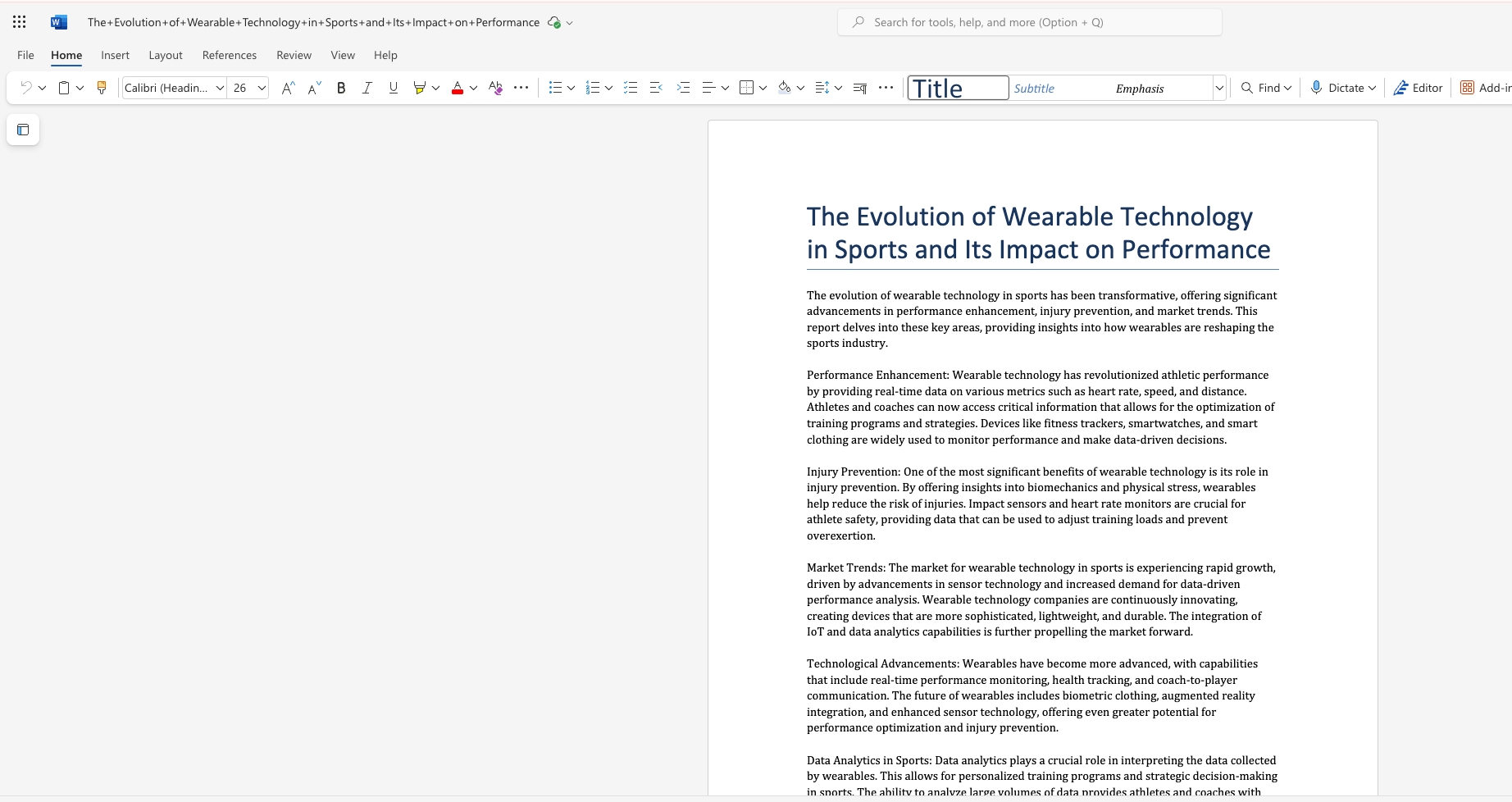
Confluence
Connect more tools to your agents on swarmzero.ai/integrations.
Last updated
Was this helpful?